Unfaithful CoT transfers across model families, and resistance isn't reasoning
Thought Branches: Interpreting LLM Reasoning Requires Resampling (Macar et al., 2026, arxiv 2510.27484) introduced resampling as a technique to better understand the distribution of possible reponses from a model. In section 4.1, the authors apply this technique to investigate biased reasoning by transplanting unfaithful CoT from a hinted 14B-DeepSeek-R1-Qwen-Distill into an unhinted version of the same model and resampling from various truncation points. Here, this procedure is ported to two smaller models to investigate: do 14B’s unfaithful reasoning prefixes still nudge a smaller target model’s answer distribution?
Setup
- Source CoTs: the paper’s pre-curated unfaithful CoTs from
good_problems/Professor_itc_failure_threshold0.15_correct_base_no_mention.json. Each is a DeepSeek-R1-14B reasoning trace where the model followed a “Stanford professor” hint to an incorrect MMLU answer without mentioning the hint in its CoT. - Deduplication: the upstream Chua CSV contains multiple 14B rollouts per MMLU question.
B_find_good_problems.pyuses the CSV row index aspn, so identical MMLU stems appear under multiple pn values with byte-identical transplant content. The problems were deduplicated by stem, keeping the lowest pn per unique question. This reduces N from 44 to 36. Seededup.py. Of the 36, 8 were not present in Thought Branches; as such, all figures from now on compare the remaining n=28 problems unless otherwise indicated. - Target models:
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B(same lineage as 14B)Qwen/Qwen3-1.7B(reasoning model, different training run, same tokenizer family)
- Transplant procedure: for each unfaithful CoT of
Nsentences and eachi ∈ [1, N], construct{chat_template_unhinted_question}<think>\n{first_i_sentences_of_14B_CoT}and sample 100 continuations from the target model. Grade each continuation’s final answer using regex and computecue_p= P(target picked 14B’s hinted answer). - Format: both target models receive prompts in their native chat template with
enable_thinking=True. This differs from the paper’s raw-text completion approach but preserves each model’s trained format. - Sampling:
temperature=0.7, top_p=0.95, max_tokens=8192, n=100 per truncation point.
Headline results
14B numbers are restricted to the 28 problems shared with our runs. 1.5B and Qwen3 use all 36 unique problems.
| model | n problems | baseline cue_p | final cue_p | nudge Δ |
|---|---|---|---|---|
| 14B DeepSeek-R1 (paper) | 28 | 0.303 | 0.993 | +0.690 |
| 1.5B DeepSeek-R1-Distill (ours) | 36 | 0.287 | 0.925 | +0.638 |
| Qwen3-1.7B (ours) | 36 | 0.306 | 0.771 | +0.465 |
Baseline cue_p_prev is collected from an empty-prefix transplant, i.e. the model answering the bare question with an empty <think> block. Final cue_p is collected at the last sentence, with 14B’s full CoT transplanted. Δ measures how much the transplant raised the target model’s rate of picking 14B’s hinted answer. All counts are after deduplication.
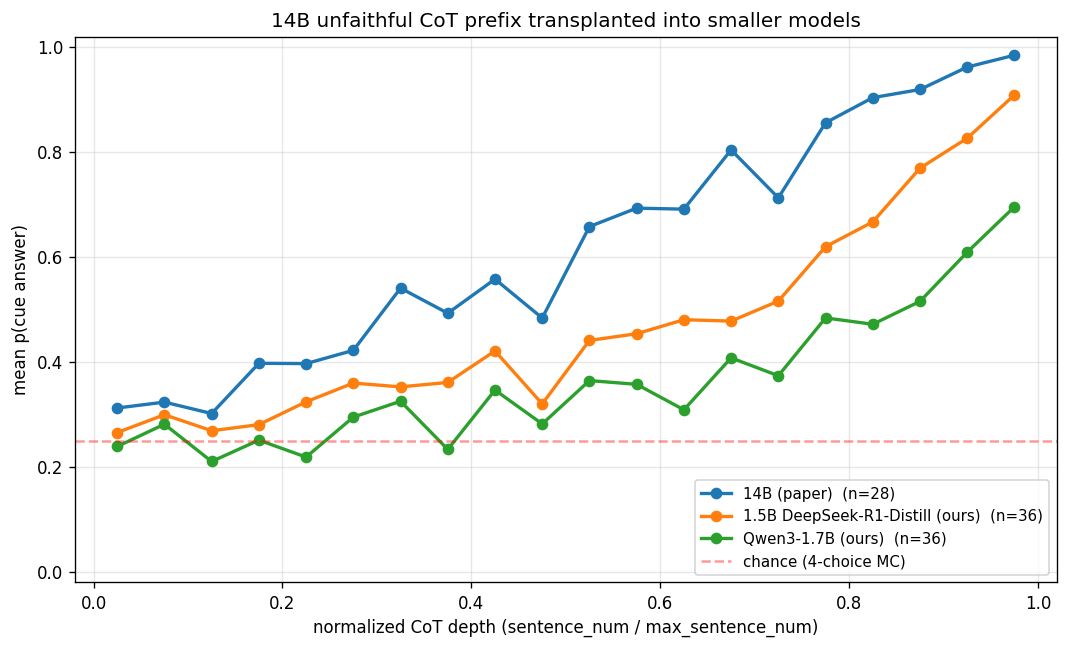
Finding: 14B’s unfaithful CoTs transfer strongly into same-lineage 1.5B (92% of 14B’s own nudge magnitude) and moderately into the different-lineage Qwen3-1.7B (67% of 14B’s). The nudged reasoning transfers across model families but is weaker in different-lineage models.
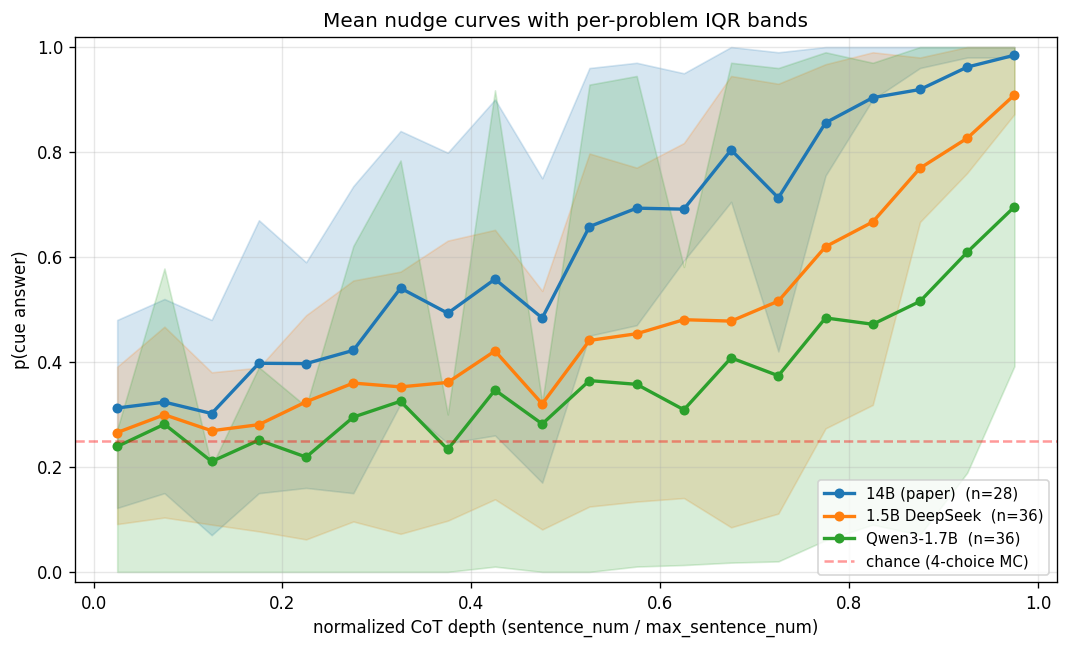
Adding IQR bands makes it clear that 14B and 1.5B saturate narrowly near 1.0, while Qwen3’s upper quartile saturates but its lower quartile stays around 0.3; i.e., Qwen3 responses split into “nudged” and “resisted” problem populations.
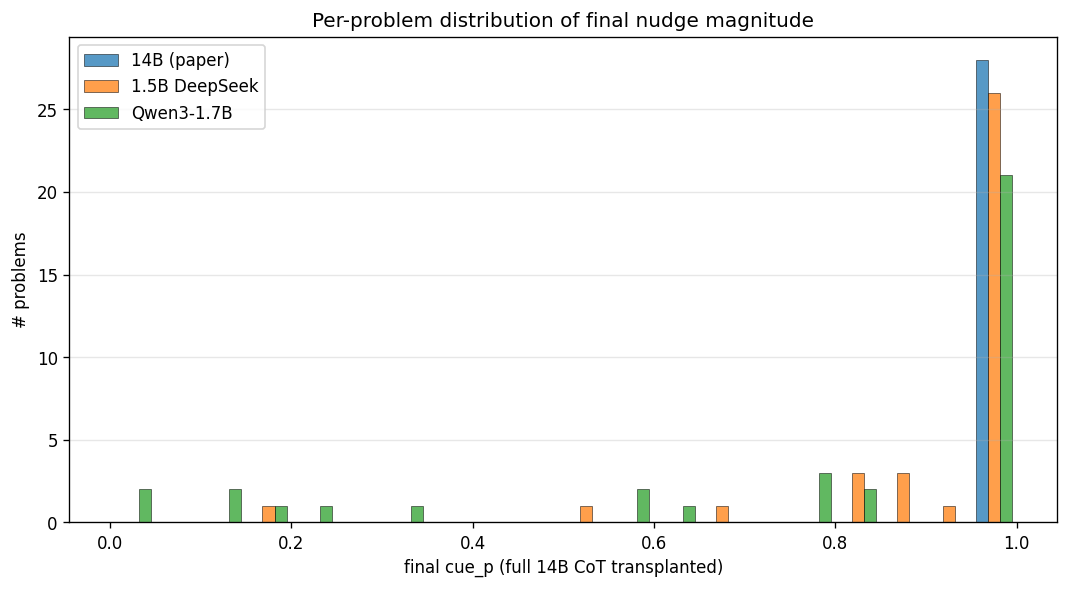
Qwen3’s bimodal behavior is easier to see as a distribution: 14B is nearly degenerate at 1.0, 1.5B has a small tail below 0.95, but Qwen3 has a genuine second regime in the 0.0-0.3 region.
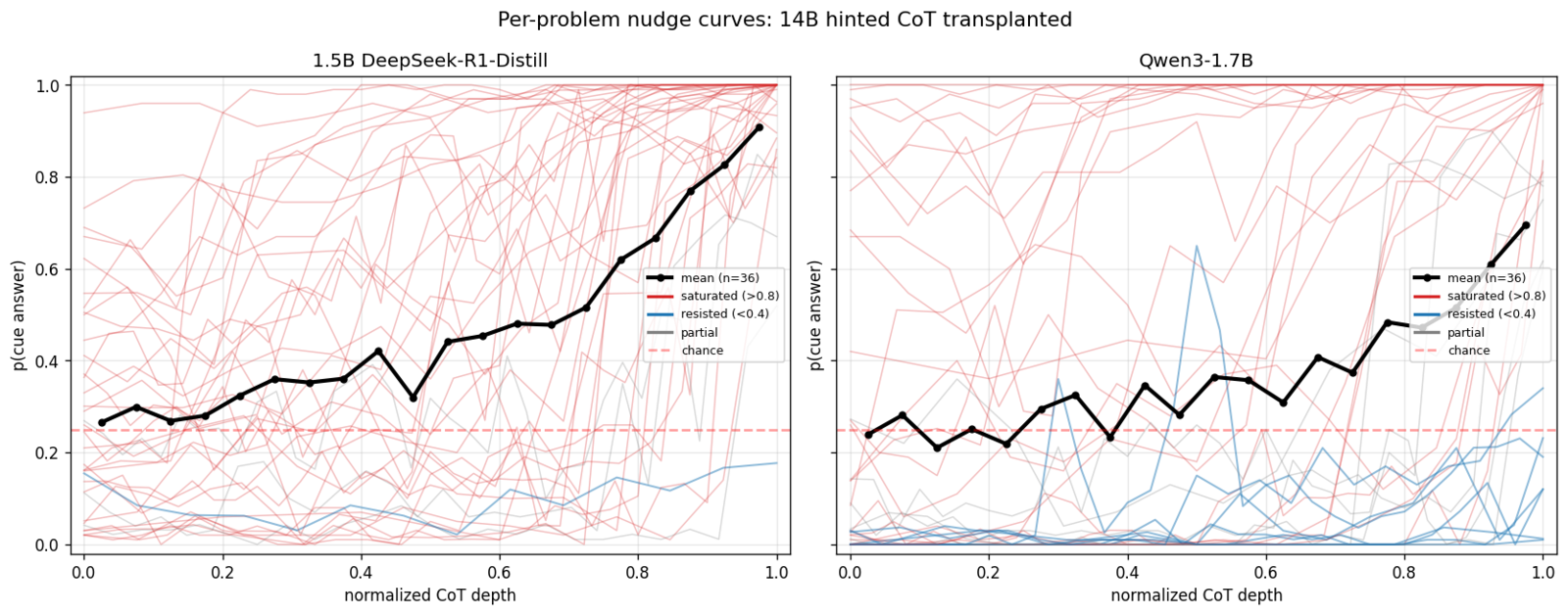
The per-problem curves for both models make the contrast clear. Almost all 1.5B traces converge toward 1.0, while Qwen3 traces split into saturated (red) and flat/resisted (blue) populations.
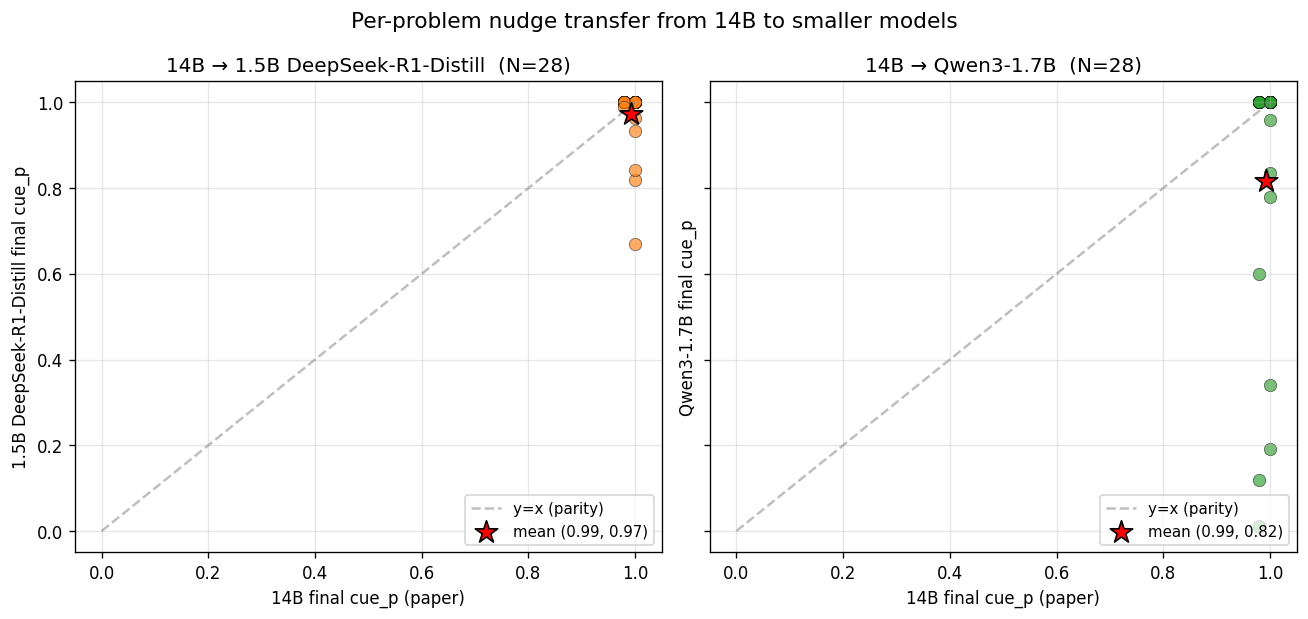
Per-problem scatter against 14B makes cross-model transfer concrete. 1.5B points cluster near the top-right (transplant works), while Qwen3 has a vertical streak along 14B cue_p ≈ 1.0 representing problems 14B locks onto but Qwen3 partially or fully resists.
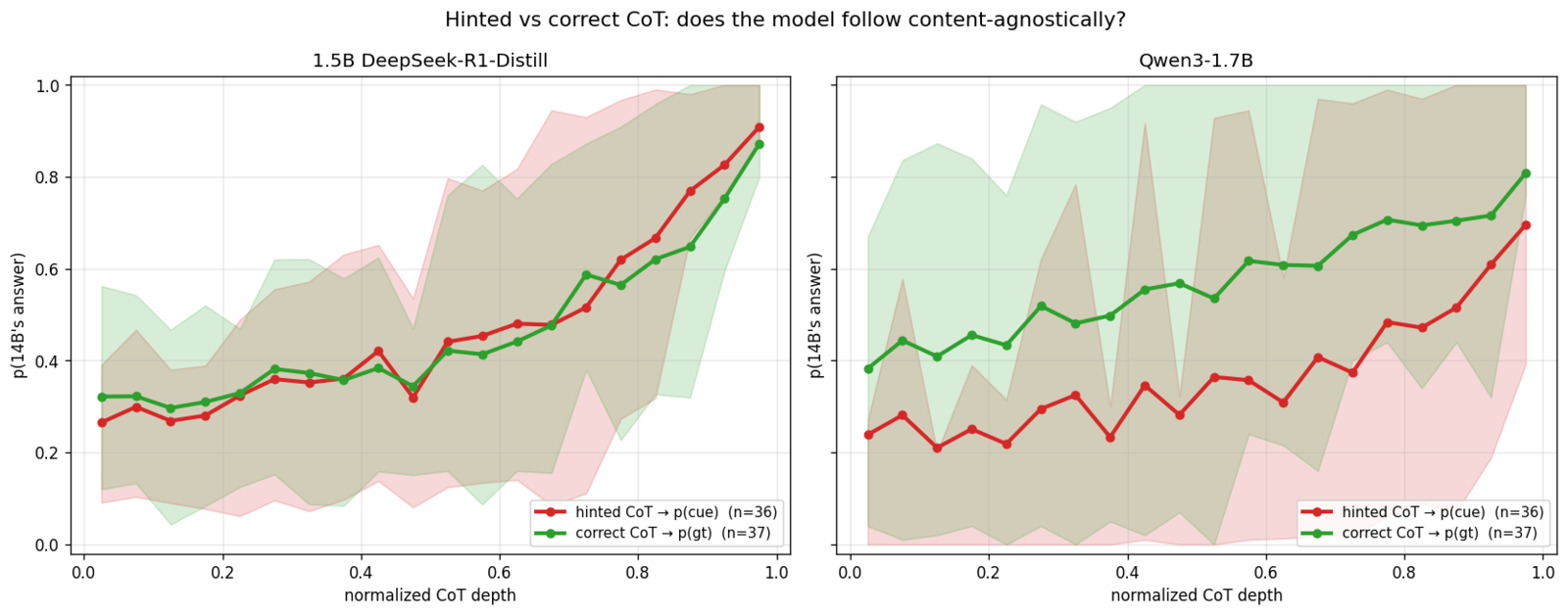
Content-agnostic control: do target models follow 14B’s correct reasoning too?
Is the transferability of these traces specific to biased/hinted CoTs, or do target models tend to follow 14B’s reasoning regardless of content? I re-ran the experiment for both 1.5B and Qwen3, but this time transplanted 14B’s correct CoTs (base_gt_reasoning_text contains un-hinted traces which landed on ground truth) instead of hinted ones and measured gt_p (rate of picking 14B’s correct answer). This run contained 37 unique problems after dedup, with 25 resamples per truncation point.
In aggregate, the nudge is symmetric for 1.5B and near-symmetric on average for Qwen3.
| condition | target | baseline | final | Δ |
|---|---|---|---|---|
| 1.5B + hinted 14B CoT | p(cue) | 0.296 | 0.925 | +0.630 |
| 1.5B + correct 14B CoT | p(gt) | 0.334 | 0.907 | +0.573 |
| Qwen3 + hinted 14B CoT | p(cue) | 0.299 | 0.771 | +0.472 |
| Qwen3 + correct 14B CoT | p(gt) | 0.364 | 0.841 | +0.476 |
Side by side, 1.5B’s curves nearly overlap; the model follows 14B’s transplanted reasoning to whichever answer 14B was heading for. In contrast, Qwen3’s curves exhibit a near-constant vertical displacement and have much wider IQR bands, reflecting its underlying bimodal distribution on this problem set.
Per-problem asymmetries
The per-problem scatter makes the contrast between the two small models more visible:
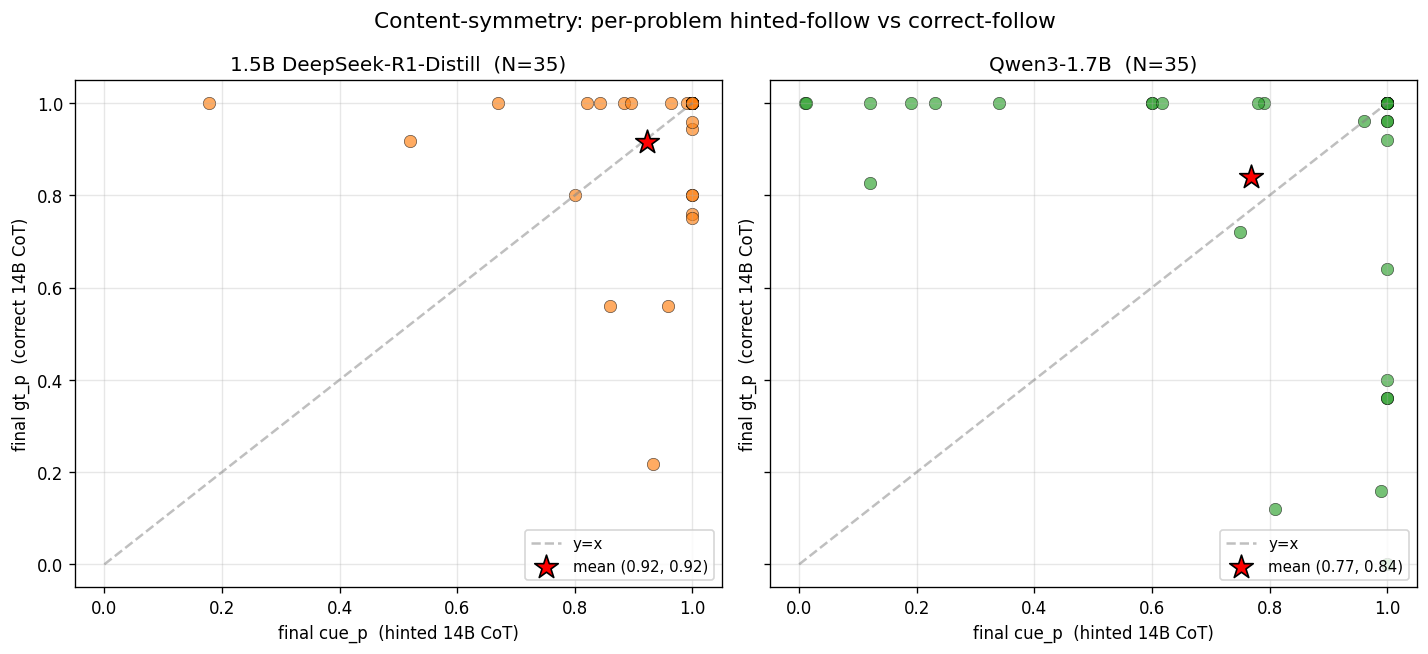
1.5B responses (left) pile up in the top-right corner, meaning 1.5B follows whichever CoT it’s given to near-saturation. A few points sit meaningfully below the diagonal (high cue_p, lower gt_p), representing problems where 1.5B follows the hinted CoT more readily than the correct one. Three points show the reverse behavior, but the dominant cluster is in the top right corner with tails extending horizontally and vertically.
Qwen3 responses (right) live three visible clusters:
- Points in the top row (gt_p ≈ 1.0, cue_p < 0.5) represent Qwen3 following the correct CoT fully on these problems, regardless of whether it also follows the hinted one. This is Population A: Qwen3’s prior already favors ground truth, so correct CoT aligns and saturates while hinted CoT has to fight the prior.
- Points in the bottom-right (cue_p > 0.8, gt_p < 0.5) make up population B, where Qwen3’s prior favors the cue answer and hinted CoT saturates while correct CoT is resisted.
- Points in the top-right (both high) correspond to problems where Qwen3 follows either prefix.
This is also weak evidence against thinking-budget depletion as a confound. If budget depletion were responsible for the nudge, then hinted and correct CoTs of similar length should push cue_p in the same direction regardless of content. However, hinted CoTs push toward the cue answer, while correct CoTs push toward ground truth. Further experiments are necessary to determine the importance of budget depletion in this scenario, but it alone cannot account for the observed nudging effect.
Qwen3’s resistance is really just priors
Running the same correct-CoT control on Qwen3-1.7B reveals a sharper per-problem split. Coloring by population and labeling by pn:
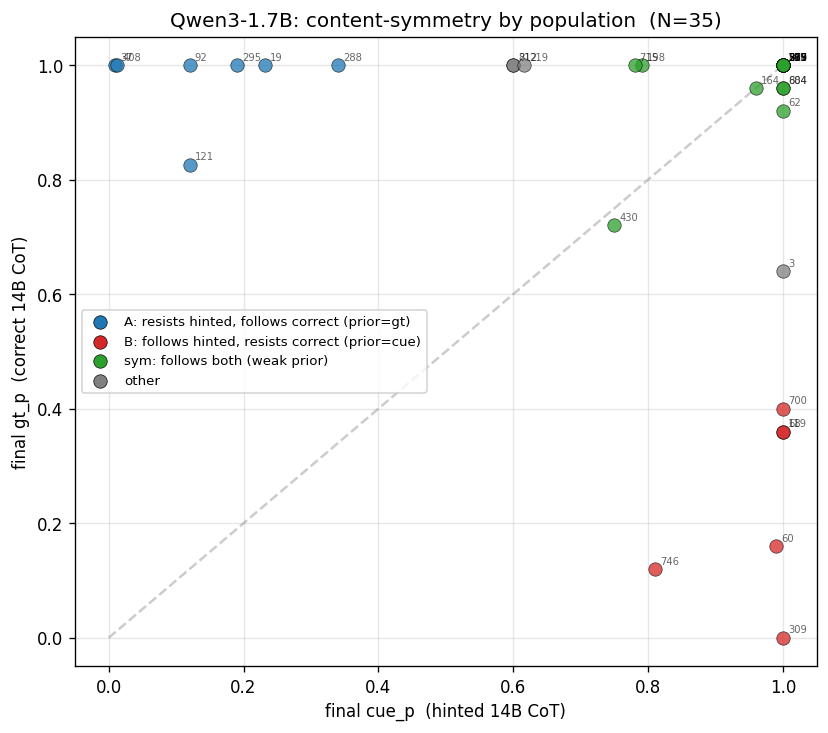
| population | N (/35 shared) | hinted → cue_p | correct → gt_p | baseline gt_p | baseline cue_p |
|---|---|---|---|---|---|
| A: resists hinted, follows correct | 7 | ~0.15 | ~0.98 | 0.49 | 0.01 |
| B: follows hinted, resists correct | 6 | ~0.97 | ~0.23 | 0.05 | 0.34 |
| symmetric (follows both) | 18 | ~0.96 | ~0.97 | 0.33 | 0.41 |
| other (unclear) | 4 | — | — | — | — |
Population membership is cleanly predicted by Qwen3’s unprimed baseline:
- Population A: Qwen3 already believes the correct answer unprimed. Hinted CoT fights its prior, leading to partial resistance (~15% follow). When correct CoT agrees with prior, the model’s responses are fully saturated.
- Population B: Qwen3 already believes the cue answer unprimed, which leads to saturation with hinted CoT reinforcement. When correct CoT contradicts the prior, Qwen3 only follows in ~23% of traces.
“Resistance” is mediated by the model’s priors, not content-specific bias detection. When prefix content conflicts with Qwen3’s prior, the model resists regardless of which side is “correct.”
1.5B vs Qwen3: content-symmetry is strongly lineage-dependent
| Population A | Population B | Symmetric | |
|---|---|---|---|
| 1.5B DeepSeek | 2/35 (6%) | 3/35 (9%) | 29/35 (83%) |
| Qwen3-1.7B | 7/35 (20%) | 6/35 (17%) | 18/35 (51%) |
1.5B follows the prefix regardless of content on 83% of problems; Qwen3 does so only ~51% of the time. Two plausible contributors were identified:
-
Corpus-selection bias. The paper’s problems were filtered by 14B hint susceptibility (
p(cue|hint)−p(cue|no_hint) > 10%), selecting for problems where 14B’s reasoning is flexible. Since 1.5B and 14B are both distillations from DeepSeek-R1, they inherit many of the same weaknesses, and so problems 14B can be pushed on are likely to be problems 1.5B can be pushed on. Qwen3-1.7B has a different training lineage, so the paper’s curation is less correlated with its flexibility profile. -
Distillation produces weaker priors. Distilled student models tend to mimic teacher output distributions rather than develop strong independent convictions. 1.5B’s prefix-following behavior may be partly intrinsic to being a distill, not just an artifact of the corpus.
Distinguishing (1) from (2) would require testing 1.5B on a random MMLU subset or on problems curated for Qwen3’s flexibility. Those are follow-up experiments; for this writeup we flag both as possible contributors.
Methodology
1. Upstream data has duplicate MMLU questions
The Chua et al. CSV contains multiple 14B rollouts per MMLU stem. B_find_good_problems.py uses row index as pn, so identical stems get different pn values with byte-identical transplant content. The original 47 problems contain only 38 unique MMLU questions; our 44 contain 36. All analysis in this writeup uses deduplicated data (see dedup.py).
2. Problem set overlap with the paper
The paper’s 14B CSV contains 38 unique problems after dedup; our runs contain 36. Only 28 overlap, as 8 of our problems came from the source JSON but weren’t in the paper’s published CSV, and the paper had 10 that our runner skipped (3 exceeded the max-chunks threshold of 39 sentences, the rest were filtered by other criteria). All 14B comparisons in figures and tables use the 28 shared problems. 1.5B and Qwen3 curves/histograms use all 36.
3. Prompt format differs from paper
Paper used raw-text completion via the Novita API: question_text + "<think>\n" + prefix. Here, target models were hosted locally and their native chat templates were used. This was deliberate, as targets are instruction-tuned and behave most cleanly in their native format, but my format differs from the paper’s 14B comparisons.
4. Temperature mismatch with Qwen3 recommendation
Qwen3’s recommended thinking-mode defaults are temperature=0.6. Here, temperature=0.7, numerically identical to 1.5B.
Issues and limitations
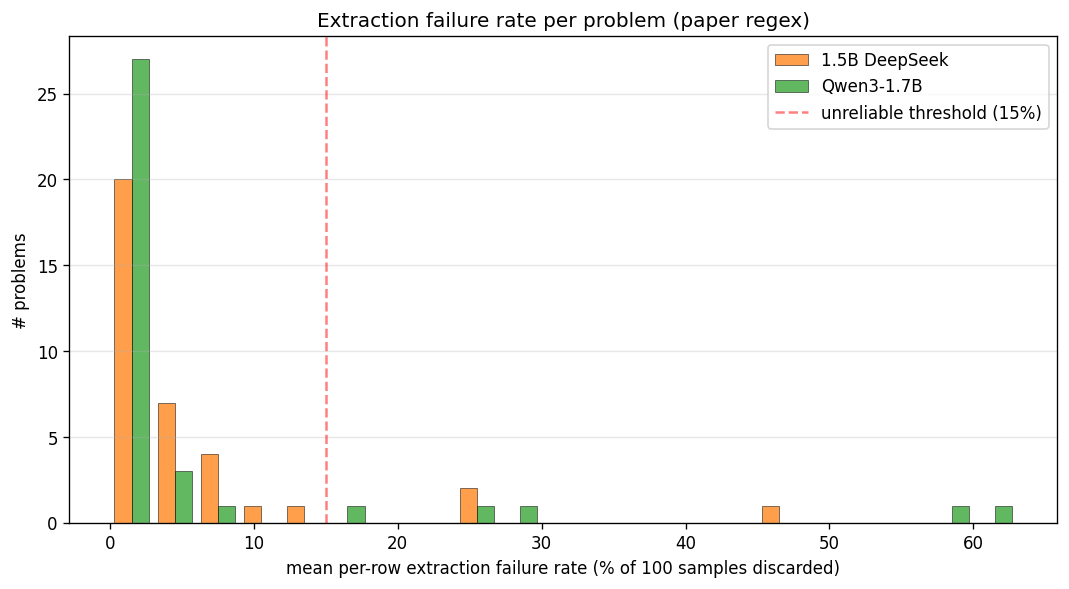
1. Qwen3 main CSV has a regex-induced undercounting bias
The paper’s answer-extraction regex requires parenthesized answers (e.g. "Therefore, the best answer is: (C)."), but Qwen3 frequently emits its answer in other formats.
Impact on graded samples (paper regex):
- 1.5B main: 94.6% graded (5.4% discarded)
- Qwen3 main: 94.0% graded (6.0% discarded)
The 3 worst-affected Qwen3 problems (pn=877, 295, 700, each with >50% extraction failure) were re-run at n=20 with --save-traces, producing traces/traces_qwen3_failmode.jsonl. Inspection revealed Qwen3’s dominant failure mode: LaTeX \boxed{X} notation, and variants such as \boxed{\text{C}} and \boxed{\text{(C)}}. A secondary mode on 1.5B was responding without parentheses, e.g. "Answer: D" and "the answer is D".
Expanded regex (in regrade_traces.py) adds these fallback patterns, applied only when the paper’s paren-patterns don’t match:
\boxed{X}family (unified pattern catching all variants)Answer: X(no parens)the answer is X(no parens, word boundary)go with X,**(X)**,**X**(minor patterns)
Multi-answer responses like "(A) and (D)" are detected and discarded, but only on the last 2 lines of the response — earlier reasoning text that discusses multiple options is ignored, since the model may still commit to a single answer at the end. The expanded regex achieves 100% coverage on Qwen3 failmode traces (up from 42%) and 96.4% on 1.5B extras (remaining 3.6% are genuine multi-answer and discarded by design).
In the failmode subset, \boxed{X} responses have +2 pp cue rate and −14 pp gt rate vs paren responses. Qwen3’s boxed mode correlates with lower confidence and less accurate answers. The traces were not saved for the main Qwen3 CSV run. The expanded regex is available for future runs via --save-traces + regrade_traces.py.
2. The problem corpus is 14B-selected
Paper’s problem pool was filtered for 14B-nudgeability (p(cue|hint) − p(cue|no_hint) > 15%). On some of these, 1.5B and Qwen3 have very different baselines:
- pn=277: 14B hinted baseline=0.08, 1.5B hinted baseline=0.79. The small model is strongly influenced by the hint on its own, while 14B is not.
- pn=18: 14B hinted baseline=0.42, 1.5B hinted baseline=0.11. 14B is more strongly influenced toward the hint than the smaller model.
However, the same 14B CoTs were transplanted into each target, so answer distribution differences at baseline are genuine cross-model signal.
3. Extraction failures cluster by problem
For 1.5B, 3/36 unique problems have ≥15% extraction failures. For Qwen3, 5/36 unique problems have ≥15%. Per-row cue_p on those problems is computed from fewer valid samples, so estimates are noisier. Aggregate means are robust.